01. 運維挑戰加劇
新時代技術背景下,運維面臨的挑戰加劇:
1)業務數量日益增加、業務規模日益龐大
隨著科技發展進步、民眾生活富足,線下業務線上化、線上業務復雜化趨勢愈演愈烈,各行各業投入巨大人力物力財力進行企業IT建設。隨之而來的是線上業務數量的爆炸式增加與業務規模的劇烈擴張,這對企業IT運維人員提出了全局把控能力的重大挑戰。
2)云原生、微服務技術應用
伴隨著業務增長,IT架構領域提出了云原生、微服務的構建理念,將傳統的大體量、高耦合應用系統拆分為微型化、可拆卸的分布式模塊。這種高可用性、高靈活度的部署架構使得運維人員更難了解系統全貌,在日常監控和故障現場還原時難度極大。
3)容器技術的大規模實踐落地
與此同時,在資源調度層面,為應對上述現狀帶來的業務快速迭代、運行保障維穩需求,容器技術在各企業內部快速落地推廣。容器對基礎資源的弱依賴、Pod/Container頻繁起滅的特性都給運維工作帶來了難以估量的復雜度提升,人力沒有算力快的“弱勢”日益凸顯。

綜上所述,在當今企業內部,運維工作越來越需要工具的協助,傳統人工式的運維方案,已無法應對科技發展帶來的挑戰要求。
02. 企業應用觀測建設路徑
面對上述挑戰,企業常常會踏上構建可觀測性工具體系的征途,而在融合ITIM基礎監控之后,針對應用的可觀測能力補充往往在中間階段進行建設落地。
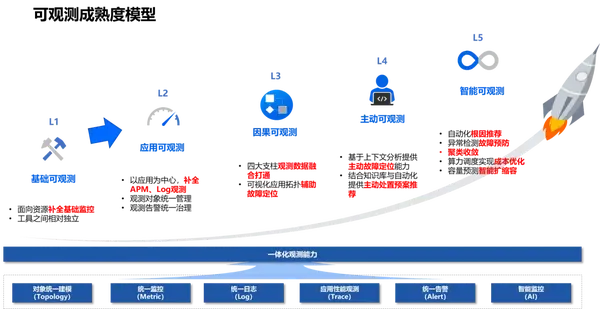
- 針對應用的可觀測體系,首先需要建設狹義上的應用監控工具(APM),通過請求跟蹤(Trace)標記,實現應用架構可視化、應用流量指標化、請求記錄數據化;
- 在觀測數據補足后,應用觀測進入下一階段建設目標——數據聯動,將應用觀測數據(Trace)和指標(metric)、日志(log)關聯起來;通過多維度視角監控業務系統運行狀況,為告警產生后的故障定位提供可追溯的現場記錄。
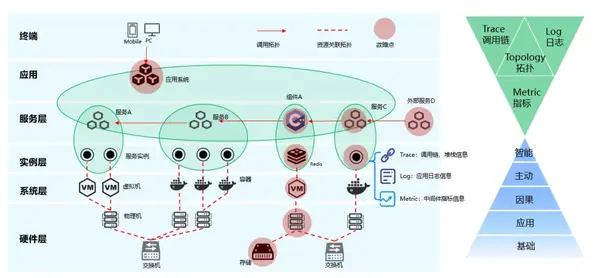
03. 企業應用觀測建設思路
1)總體定位
鏈路追蹤的工具,即前面提到的APM,因為其自動化生成了一系列數據之間的關聯關系,在整個可觀測體系中是一個類似中樞的存在。
這張圖概括了鏈路追蹤在整個可觀測體系建設中的定位以及與其他工具的關聯關系:
- 向前可關聯到用戶操作,鏈路追蹤可以將用戶在終端上的發起的請求和后端鏈路聯系起來,實現前端到后端完整的時間線和因果關系呈現;
- 向后則可串聯到具體日志,鏈路追蹤可以定位到具體某個服務的某次或某一批請求,從而精確匹配到相關日志來解析問題所在;
- 向下則可以在鎖定某個服務節點問題后,通過資源標簽定位到具體承載這個服務節點的進程級監控和主機操作系統層級的監控,或是容器平臺的監控。
另外鏈路追蹤本身也是可以進行一些指標提取的,經典指標例如請求量、請求成功率、各種分位的時延,這些指標在配置了一定的告警規則后,也都可以直接作為告警來源。產生異常后主動觸達運維人員。
由此可見,在構建全面的可觀測性體系時,孤立地看待與應用性能管理(APM)工具的建設是一種偏頗的思路。不少企業曾嘗試獨立為APM工具設立項目并推進實施,然而最終這些工具并未能實現廣泛的采納與應用,項目所帶來的實際效益遠低于初始預期。究其根本,是因為單一的APM工具所能覆蓋的問題場景極為有限。我們應當將APM盡可能和各類其他觀測工具做串聯打通,通過APM建立起基于業務實際請求流量的“橋梁”,有目標性地拉通各個觀測工具和不同類型的觀測數據,實現完整有效的觀測效果。
接下來我們就具體的串聯打通場景提出一些具體實踐供各位讀者參考。
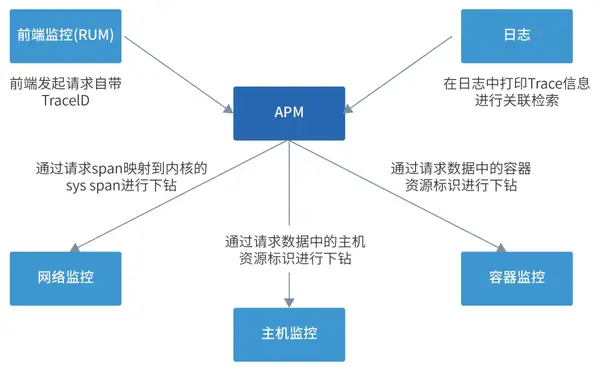
① 前端到后端串聯排障
當具備對用戶終端數據進行采集的能力,那就可以結合這種前端監控工具(RUM)和鏈路追蹤工具(APM)通過一些機制來實現前端到后端的串聯排障。

圖中可以解釋這一過程的原理,用戶在移動應用或者Web瀏覽器網頁上訪問時,會生成一個Session被記錄,一個Session中記錄了一個用戶的完整操作流程,包括他依次打開了哪些頁面,在每個頁面上進行了怎樣的操作,觸發了哪些后臺請求。當產生了一個具體的后臺請求后,RUM工具可以按照APM工具定義的Trace標識規則(TraceID的生成規則),來對這個請求進行標記,這樣在后端也可以完整跟蹤到這個請求在后端系統具體經過了哪些服務,在哪個服務上處理消耗的時間過長或者出現了報錯。
② 鏈路跟蹤與日志關聯
對于開發人員來說,直接將問題定位到代碼級別是最高效的。但告警信息的有限以及指標類數據的高度抽象,使得運維人員在很多時候其實無法給出這么詳細的信息,無法有效輔助開發人員進行問題定位和解決。這時,鏈路追蹤和日志關聯的方式就給出了一種有效的解決手段。
具體的實現方式如下圖所示:
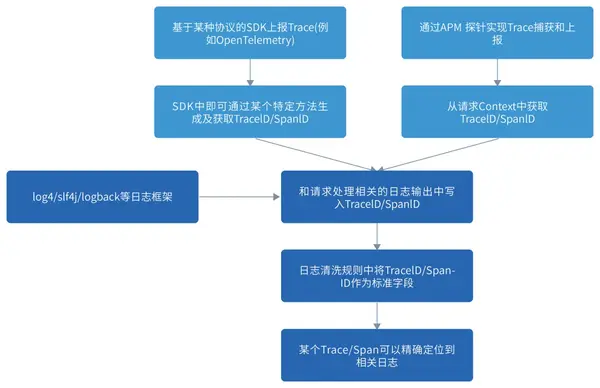
可能會有工程師擔心這種方式對代碼侵入性很大,很難實踐,但其實不然,業界有非常多好用的日志框架來幫你解決這個問題,我們只需要額外生成一份日志輸出的配置文件做批量下發即可。
以下就用Logback日志框架配合Skywalking探針(一種業界流行的開源APM探針)來做個例子,其中關鍵的修改點在于:
- 引用skywalking官方提供的工具類

- 在Logger配置中引用這個Appender

在這個過程中,業務并不會有很大感知,只是會發現他們輸出的日志中增加了Skywalking注入的TraceID等信息。接下來我們在日志解析過程中就可以提取這些Trace信息,便于后續直接根據這些Trace信息進行關聯檢索和分析。
③ 鏈路追蹤下鉆到資源層監控
這里會進一步分為三種不同類型的場景:
- 下鉆到組件或數據庫排查問題
APM所捕獲到的調用數據中,有一部分是對組件或數據庫的調用。這種調用可以將系統所用到的組件和數據庫直觀地呈現在拓撲圖和某一條具體的調用鏈中,如果相關的組件或數據庫出現了問題,大概率會在這種可視化的形式中有所體現,例如拓撲圖上的狀態呈現以及調用鏈瀑布圖中的長條。當然,這里只是解決了發現的問題,我們只能在APM中判斷這些組件或者數據庫的故障對上游調用者產生了影響,但至于為何產生以及這些組件及數據庫的真實運行狀態,我們仍然需要借助其他監控工具來呈現和分析。
此時APM可以在調用信息中提取出對應組件或數據庫的資源標識,這可能是IP地址,或是域名鏈接,再通過這些標識信息去對應的組件監控或數據庫監控中獲取到這些資源的核心監控指標信息及相關日志,通過同一個平臺的頁面跳轉或者嵌入來實現一套連貫的排障流程,提升此類場景的排障效率。
- 下鉆到進程所在的主機/容器集群排查問題
當我們在系統中通過APM探針或者SDK按照規范要求上報了Trace信息,一般都會攜帶對應服務所在的主機或者容器集群信息,最常見的就是主機的IP地址以及容器的ContainerID,這兩種信息會作為我們去尋求其他監控工具時對主機和容器監控的索引,從而能夠在識別到某個服務節點故障后,對其所在的主機或者容器進行下鉆,查看到主機和容器層級上更加精確的指標數據或者容器數據。
- 下鉆到網絡行為分析網絡問題
我們知道,計算機網絡其實底層有七層協議,而我們平時大多數情況會將這七層協議轉化抽象成單次請求。但不排除,有時我們的故障發生在比較深的網絡層面,在APM調用鏈中只能得知某一段span的耗時增加、返回碼錯誤或者無響應斷鏈,無法進一步排查深層次的網絡問題。這時就可以通過這一進程將請求的span獲取到內核態的 sys span ,再從sys span映射到網絡監控中的具體net span,然后就可以從專業的網絡監控中獲取到這次網絡請求在各個環節的詳細信息。
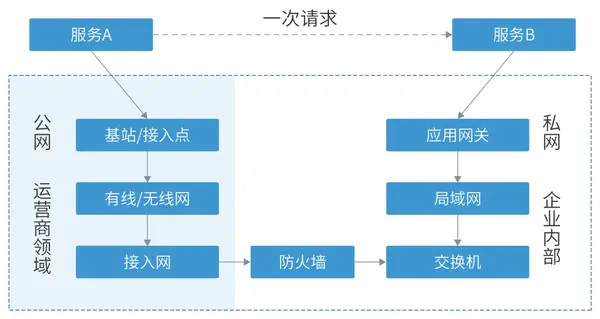
通常某次請求出現網絡問題的概率還是比較小的,往往是短時間大面積出現網絡問題,這個時候我們也可以從APM的某些樣本請求中獲取一個大致的范圍,接下來按一定條件跳轉到專業的網絡監控,查看相應的指標趨勢(例如丟包數量、丟包率、CRC校驗通過率等)。
04. 結語
以上,我們介紹了比較成熟理想的企業應用觀測中樞建設方案。總的來說,應用觀測領域目前尚處于快速發展、落地探索階段,各企業在建設應用觀測中樞的過程中不應操之過急。企業內部從一個試點出發,以點帶面,逐漸推廣是比較理想且穩妥的建設節奏。其最終實現的觀測能力也將會對企業內部的系統維穩及代碼調優起到極大的助力作用。











